Even if you don’t work in a technical field, chances are that you’ve heard of the term “DevOps” which relates to how software is developed, maintained and delivered within a business. DevOps is not suitable for an end-to-end machine learning solution because traditional software system behaviour is generally governed by fixed rules specified in code. On the contrary, ML system is very dynamic and far more complex, making it very difficult to apply DevOps principles.
MLOps is a set of practices which allow us to develop, deploy and maintain machine learning solutions so that they consistently produce trusted results.The MLOps life cycle is illustrated below and includes
- Model Building
- Evaluation and Experimentation
- Deployment (includes testing)
- Monitoring
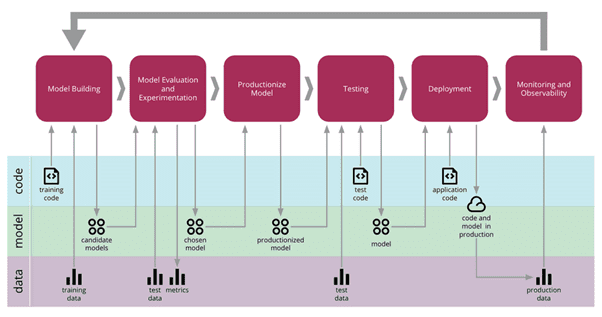
In this blog I will only discuss model monitoring.
Post-deployment, the monitoring framework will be the deciding factor of the machine learning project’s success or failure.
Any business that relies on machine learning – be it for a chatbot, recommendation engine, predictive modelling and so on – has ROI that is directly dependent on the model developed to achieve the business’s specific outcome. These machine learning models form a quintessential decision system in modern businesses; hence It is critical that these models stay in context and do not decay with time.
Why do machine learning models degrade?
Performance of the model reduces over time; this is referred to as model drift. This happens when the data being fed into the model is different to the data it was trained on.
- Change in data distribution – This happens when data has different distributions during training and serving e.g. model trained on historical data will need to anticipate changes in current data.
- Shift in user behaviour – This may occur generally with recommendation models where user behaviour shifts either due to individual circumstances or because of drift in fashion and political trends.
- Feature Relevance – Sometimes features present in training data become irrelevant or unavailable in production. One of the reasons this happens is because the features are generated from different systems, or they have been combined to corelate with ones in training.
Monitoring: Mitigate degradation
While almost everyone in the AI and machine learning space agree that machine learning models should be monitored to ensure optimal performance, the hard truth is that very few are. One of the most common reasons for this is that it is notoriously difficult.
In a standard software project, we can quite easily code a set of rules and then map them to provide an instant alert if the software fails. With machine learning however, you are not just working with code but with changing data and a model. With all 3 components in constant flux, it’s much more difficult to set up a system of rules to trigger an alert if the model fails.
How to do general purpose model monitoring
The basic idea is to collect metadata during the monitoring phase and set up a feedback loop to model the deployment stage. This enables us to decide whether to update the model or continue with the same model. MLOps allows for the collection of metadata like data comparison stats (training and test), data on different experiments and versions of models.
A basic model monitoring system should at least consist of the below metrics:
- Stability metrics: These metrics capture data distribution shifts and depend on both data and the model. These fall into two categories:
- Category I: Calculates the Population Stability Index (PSI) and determines prior probability of distribution shift of output feature between training and production. e.g. Let’s say we want to train a cancer detection model, now we know in order to combat bias we should have 50% cancer and 50% non-cancer patients in the dataset. But in actuality we might only have 2% cancer patients, this drift will be calculated by PSI. PSI values can be set as per the problem but generally if PSI value is >0.15, we must retrain the model.
- Category II: These capture covariate shifts and drift in feature distribution.
- Performance metrics: These are inherent to model and include accuracy, model scores, ROC, Gini index etc. These can be easily monitored, and alerts can be raised once they go below the accepted benchmarks.
- Operation metrics: Independent of the data and the model, these give state of the system in which model is running and include
- Model usability: how much time it takes for a model to return result (serving latency)
- System health: I/O, memory usage, Disk utilisation.
Model monitoring in practice
All the major cloud providers support model monitoring frameworks one way or other. Let’s focus on Microsoft Azure.
Here is the architectural view for Azure machine learning using CI/CD.
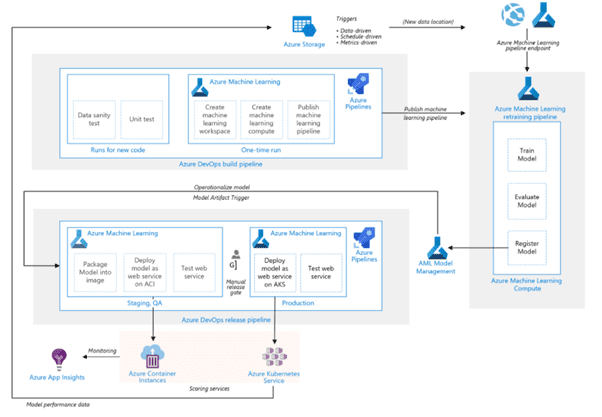
Benefits of Azure machine learning
- Reproducible ML pipelines using Azure DevOps
- Reusable software environments for training and deploying models
- Readily track associated metadata needed for model
- End-to-end ML lifecycle governance
- Manage events in the ML lifecycle e.g. experiment completion, model registration, model deployment, and data drift detection
- Monitor ML applications for operational and ML-related issues. Compare model inputs between training and inference, explore model-specific metrics, and provide monitoring and alerts on your ML infrastructure
- Automate the end-to-end ML lifecycle with Azure Machine Learning and Azure Pipelines. Using pipelines allows you to frequently update models, test new models, and continuously roll out new ML models alongside your other applications and services
To find out more about how Antares can support your business with machine learning models and MLOps, please contact us.